| ||
●1 障害件数が減らないのはなぜか?テストには、単体テスト(UT)、結合テスト(IT)、システムテスト(ST)、ユーザ受入れテスト(UAT)などの工程がありますが、私の経験からいうと最も障害が発生する確率が高いテストは結合テストだと思います。 なぜ、そんな事になるのかというと以下のような理由からです。 ①単体テスト工程が、関数レベルのテストとなり、ビジネスロジックとしてのテストがされない。 ②単体テスト工程で完全なテスト項目を作り上げ、完全なテストを実施する事はまれである。 では、どうすれば結合テストにおける障害件数を抑制する事が出来るのでしょうか? 結合テスト以降の障害件数を少なくするには、以下のようにテストを実施すれば良いのです。 ①ビジネスロジックレベルのテストを単体テスト工程で実施する。 ②ブラックボックスレベルで完全なテスト項目によるテストを実施する。 しかし、実際には、結合テスト以前にビジネスロジックレベルのテストが実施される事はまれです。 何故かというと、JUnitなどの単体テストツールを利用しても、ビジネスロジックレベルのテストを実施するにはかなりのコーディングを する必要があるからなのです。 それでは、ビジネスロジックレベルのテストを、コーディングをしないでテストする事はできないでしょうか?ビジネスロジックは、沢山の情報を入出力として利用する為、int型、double型、String型などの型では、引数が多くなりすぎてしまいます。従って、ビジネスロジックのテストを実施しようとした場合、入出力は、オブジェクトを利用します。 この入出力で利用するオブジェクトをテキスト化してテストケースのデータとする事によって、テストを簡単に自動化して実施する事が可能となります。 ●2-1 ビジネスロジックをテストする(サンプルのセットアップ)ダウンロードしたファイルを解凍し、プロジェクト名をAutoTestとしてEclipseにインポートして下さい。(この汎用プログラムは、Eclipseでの起動を前提としています。) 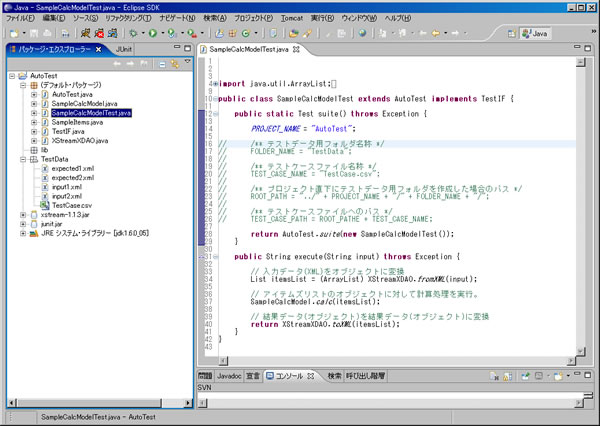
●2-2 ビジネスロジックをテストする(サンプルの実行)サンプルを実行するには、SampleCalcModelTestクラスをJUnitテストで実行して下さい。JUnitを実行すると、TestCase.csvファイルに定義した想定入力データファイル、結果データファイル、想定結果データファイルごとに1件のテストケースと して、ビジネスロジックが自動的にテストされます。その時、テストモジュールは以下のように動作します。 ①テストケース(CSV)を読み込んで、対象行がなくなるまで1行ごとに(②~⑦を繰り返し)テストを実施する。 ②想定入力データ(XML)を読込んで、オブジェクトに変換する。 ③ビジネスロジックに、オブジェクトをセットして、処理を実行する。 ④ビジネスロジックから、処理後のオブジェクトを取得して結果データ(XML)に変換する。 ⑤結果データ(XML)を保存して、読込む。 ⑥想定結果データ(XML)を読込む。 ⑦結果データ(XML)と想定結果データ(XML)を比較して、差異をチェックする。 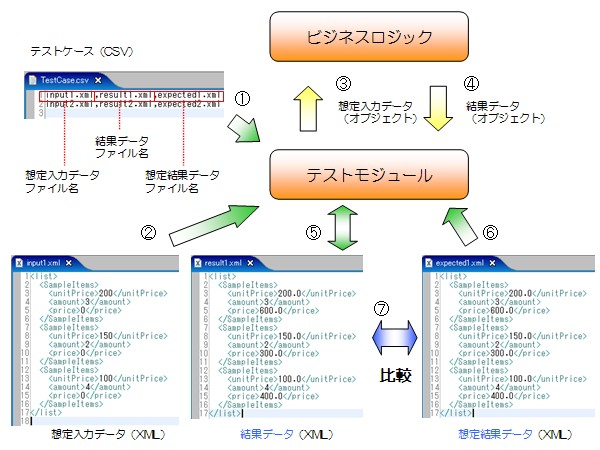
●2-3 ビジネスロジックをテストする(起動用クラスの解説)実際に、ビジネスロジックを作成する場合に最低限必要なものは、テストケースファイル(TestCase.csv)、想定入力データファイル(input.xml)、想定結果データファイル(expected.xml)、それから、JUnit起動用クラス(AutoTestクラスを継承し、TestIFクラスをimplements)になります。JUnit起動用クラスは以下のようになっています。
import java.util.ArrayList;
import java.util.List;
import junit.framework.Test;
public class SampleCalcModelTest extends AutoTest implements TestIF {
public static Test suite() throws Exception {
PROJECT_NAME = "AutoTest";
// /** テストデータ用フォルダ名称 */
// FOLDER_NAME = "TestData";
//
// /** テストケースファイル名称 */
// TEST_CASE_NAME = "TestCase.csv";
//
// /** プロジェクト直下にテストデータ用フォルダを作成した場合のパス */
// ROOT_PATH = "../" + PROJECT_NAME + "/" + FOLDER_NAME + "/";
//
// /** テストケースファイルへのパス */
// TEST_CASE_PATH = ROOT_PATHE + TEST_CASE_NAME;
return AutoTest.suite(new SampleCalcModelTest());
}
public String execute(String input) throws Exception {
// 入力データ(XML)をオブジェクトに変換
List itemsList = (ArrayList) XStreamXDAO.fromXML(input);
// アイテムズリストのオブジェクトに対して計算処理を実行。
SampleCalcModel.calc(itemsList);
// 結果データ(オブジェクト)を結果データ(オブジェクト)に変換
return XStreamXDAO.toXML(itemsList);
}
}
JUnit起動用クラスを作成する場合に、コーディングが必要な箇所は、executeメソッドの部分のみです。①想定入力データ(XML)をビジネスロジックが必要な型の想定入力データ(オブジェクト)に変換する。 ②ビジネスロジックにオブジェクトをセット、処理を実行して、結果データ(オブジェクト)を取得する。 ③結果データ(オブジェクト)を結果データ(XML)に変換する。 ①、②、③以外の動作は、テストケース(TestCase.csv)、想定入力データ(XML)、想定結果データ(XML)を利用してAutoTestクラスで自動的に処理されます。
public String execute(String input) throws Exception {
// 入力データ(XML)をオブジェクトに変換
List itemsList = (ArrayList) XStreamXDAO.fromXML(input); ・・・・・①
// アイテムズリストのオブジェクトに対して計算処理を実行。
SampleCalcModel.calc(itemsList); ・・・・・②
// 結果データ(オブジェクト)を結果データ(オブジェクト)に変換
return XStreamXDAO.toXML(itemsList); ・・・・・③
}
●3 処理結果処理結果は通常のJUnitと同じです。 結果データと想定結果データに差異がある場合には、テストケースは失敗します。その場合は、失敗しているテストケースを選択し、障害トレースをダブルクリックして下さい。すると下図のように結果比較のウィンドウがポップアップします。 (例では、わざと失敗するように故意に正しくない想定結果データを用いています。) 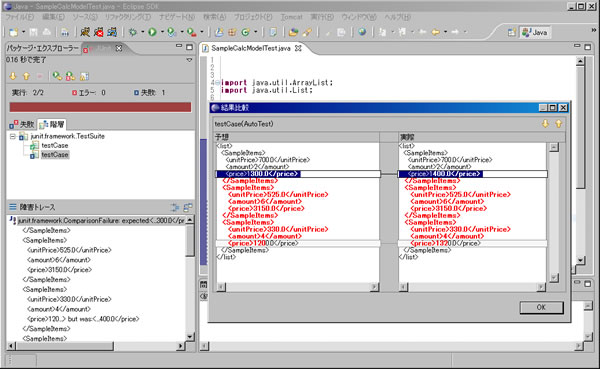
●4 クラス図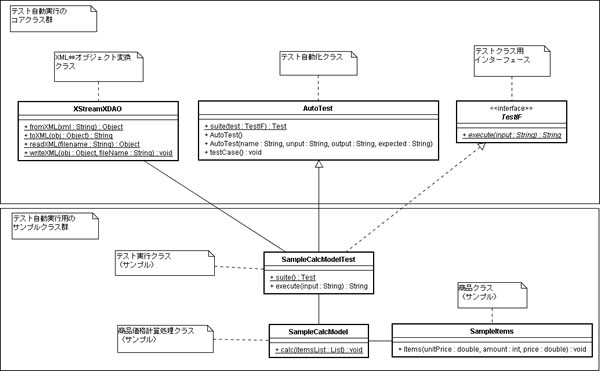
|
| 著作権について | |
| ● | 掲載されたプログラムコード、サンプルデータ、その他の情報は、ご自由にご利用ください。あなたのプログラムにコピーして利用したり、改良して公開したりすることは大いに歓迎いたします。 |
| ● | 掲載されたプログラムコード、サンプルデータ、その他の情報の著作権は、作成者にあります。著作物をパブリックドメインに置いて著作権を放棄するのではなく、著作物の独占を防ぐために著作権を主張しています。 |
| ● | 掲載されたプログラムコード、サンプルデータ、その他の情報を利用したことによって生じたいかなる損失や損害に対して一切責任を負いません。 |
| 戻る |
株式会社 オープン・システム・ソリューションズ |
|
|
Copyright ©
OpenSystemSolutions Inc. All Rights Reserved.
|